
Parsing 1 Billion Rows in Bun/Typescript Under 10 Seconds
Inspired by the 1BRC (1 Billion Row Challenge, originally in Java), I decided to write one in Bun/Typescript.
This post explains how I used Bun to process a 1 billion row file (13.8GB) in under 10 seconds. I walk through the various Bun APIs I considered, Byte processing, chunking strategies, and thinking through IO vs CPU workloads.
Check out the final solution in my github repo.
Ground rules
- Return the max, min, avg for each station.
- Make it fast
- No external libraries allowed
- Computations must happen at runtime
- File schema:
station_name: non null utf-8 stringtemperature: non null double from -99.9 to 99.9 inclusive
// sample input
Tel Aviv;33.9
Dhaka;36.9
Baghdad;29.3
Ndola;37.2
Nakhon Ratchasima;30.7
...
// output
{Abha=-35.8/18.0/66.5
Abidjan=-25.6/26.0/75.6
Abéché=-20.4/29.4/79.0
Accra=-22.3/26.4/76.4
...}
Re-creating the 1B row file
Instructions here. If everything went as planned, you’ll end up with 13.8GB file (!!).
Early Attempts
My brute force approach was to read the entire file in memory. My machine has 48GB, so that should be enough for a 13.8GB file, right?
const buffer = readFileSync("measurements.txt");
Unfortunately, no. Apparently, Bun sets a hard limit on how much RAM it assigns to a Buffer...
9 | const buffer = readFileSync("measurements.txt");
^
ENOMEM: not enough memory, read 'measurements.txt'
path: "measurements.txt",
syscall: "read",
errno: -12,
code: "ENOMEM"
at /Users/taekim/Documents/projects/1br-tae/main.ts:9:16
Bun v1.2.9 (macOS arm64)
What fs.readFileSync does:
Immediately opens the file, allocates a Uint8Array big enough for the whole thing, blocks the event-loop while the kernel fills that buffer, and then returns it.
Upon some digging, I learned that Buffers are capped at 4GB. But why?
In Bun and NodeJS, Buffer extends Uint8Array, which is a 32-bit unsigned int. And a 32-bit unsigned int can have a limit of 4,294,967,295 bytes (2^32), or 4GB.
I’ve hit OOM errors before for a NodeJS app with a “upload your file” feature like this (ex. machine runs out of buffer memory due to multiple users uploading large files at once), so this made sense.
Buffering…
Since we can’t load the entire file in memory, let’s try breaking the file down into smaller chunks, then reading each chunk separately.
A little overwhelming, but turns out there several ways to open files in Bun. Who knew?:
readFileSync
Synchronous. Loads the entire file into memory and returns a Buffer or decoded value. Best for small files.
Bun.file() + .text()
Async. Loads entire file into memory and returns decoded utf-8. Best for small files.
openSync + readSync
Loads file into a set Buffer size as a raw Bytes (Uint8Array). Best for large files.
createReadStream + readline
Processes file in chunks and decodes utf-8 for you. Best for line by line processing.
Because this is a large file, the last two made the most sense. I picked the 3rd approach because I don’t need to process any strings yet, just read the file without crashing.
Here’s how it works:
fs.openSync(): open the file; returns the open file’s file descriptor numberfs.readSync(): read the file using a given buffer size; returns the total bytes read
File descriptors are useful here because you open the file once, save a reference to that opened file, and read it whenever you need to. This way, you don’t have to open + read it every time.
import * as fs from "fs";
const filePath = "measurements.txt";
const fd = fs.openSync(filePath, "r");
const BUFFER_SIZE = 1024 * 1024 * 1024 * 4; // 4GB buffer? 🤔
const BUFFER = new Uint8Array(BUFFER_SIZE);
try {
let cursor = 0;
let bytesRead = 0;
while (true) {
bytesRead = fs.readSync(fd, BUFFER, 0, BUFFER_SIZE, cursor);
if (bytesRead === 0) {
break;
}
cursor += bytesRead;
}
} finally {
fs.closeSync(fd);
}
Notice that we can set a buffer size when opening the file. Should we use 4GB or 128KB? Why? I did some playing around and got the following:
- 4GB buffer: ~0.985 seconds
- 128KB buffer: ~0.735 seconds (sweet spot)
- 256KB buffer: ~0.765 seconds
- 1MB buffer: ~0.763 seconds
You’ll notice that anything larger than 128KB has diminishing returns. This is because Bun and the kernel is optimized for smaller buffers like 16-128KB.
An aside on kernels and pages
Specifically, programs run fastest when each read request is roughly the size of a few kernel ‘readahead’ pages (64-128KB). Once you allocate buffers in the gigabyte range, all that work to reserve virtual memory - allocating a buffer, filling every page with 0s the first time it’s touched and later having the GC scan it, etc. outweighs the savings of doing fewer reads.
💡 What’s a kernel ‘page’ and ‘readahead’ page?
A page is the smallest unit of disk data the kernel moves into RAM at once. On most modern desktop and server machines that size is 4 KB (I later discovered it’s 16KB in Apple-Silicon Macs).
When the kernel notices the user accessing the same file over and over, it pre-fetches more pages from the disk to be more I/O efficient. This is the readahead buffer.
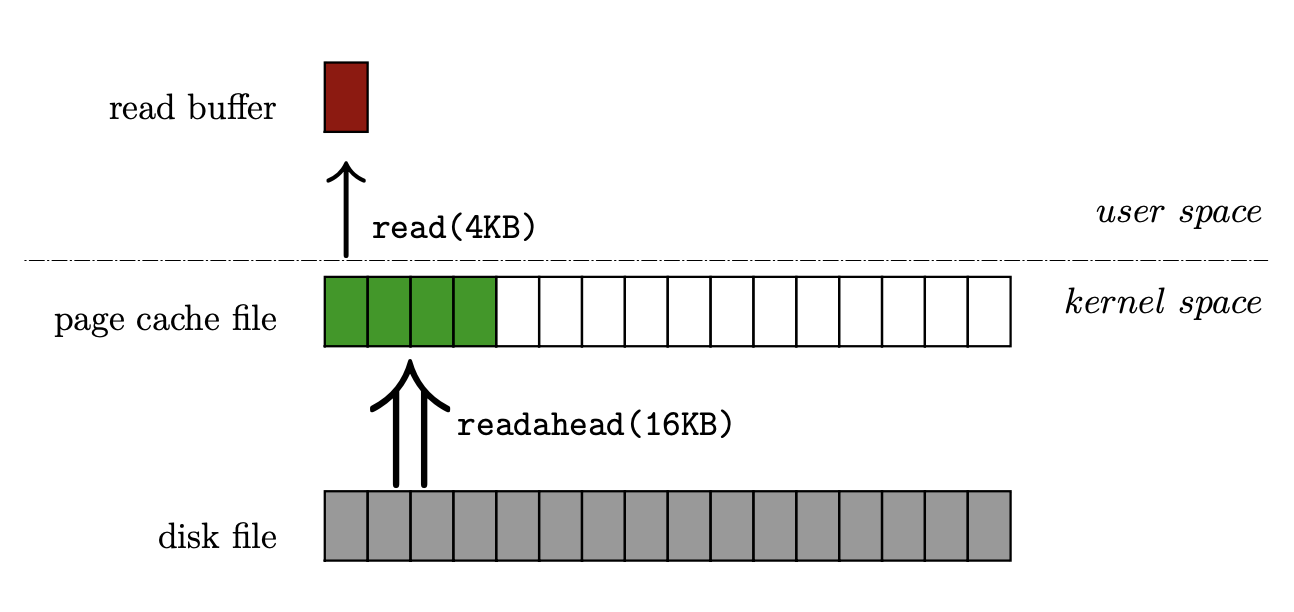
Analogy:
It’s like when the waiter (kernel) notices you keep finishing your drink (page), so the second and third time around it brings extra glasses (extra pages) for you just in case.

Drawn by yours truly
TLDR: I changed BUFFER_SIZE to 128KB and boom, we’re in business:
// runs in <1 sec 😎
// For now, all this does is read the 13.8GB file without crashing.
import * as fs from "fs";
const filePath = "measurements.txt";
const fd = fs.openSync(filePath, "r");
const BUFFER_SIZE = 1024 * 128; // <======= ✨ 128KB ✨
const BUFFER = new Uint8Array(BUFFER_SIZE);
try {
let cursor = 0;
let bytesRead = 0;
// Read the file, one buffer size at a time
while (true) {
bytesRead = fs.readSync(fd, BUFFER, 0, BUFFER_SIZE, cursor);
// base case: reached EOF
if (bytesRead === 0) break;
cursor += bytesRead;
}
} finally {
fs.closeSync(fd);
}
So far, all this code does is open the page and read in chunks.
- Allocate a buffer in memory at 128KB
- Initialize a cursor to keep track of which Bytes to read next
- Repeatedly read the file in 128KB increments
- Loop until we reach the end
Great! Now that we can read the file without crashing, let’s start doing calculations on it.
Chunking and Processing
As the 1brc prompt states, we have to aggregate each station’s min, max, avg too.
Pseudocode:
- Read the large file in chunks (make sure to keep chunks below 4GB)
- Parse each line to string (utf-8), get the
station_nameandtemperaturevalues by splitting by semicolon ‘;’ - Keep an aggregate count, min, max for each station in a hash map
- At the end, group by
station_nameto compute the average (using count)
There’s two potential ways to do this:
- Async. Each file chunk does the read + math operations. Await them in a Promise.all
- Spin up a worker for each file chunk and do the read + math there
Let’s think about the work involved:
For each chunk, we have to read and decode it as utf-8, parse the station_name and temperature for each line, put it in an hash table, and compute its min, max, and count values.
This is both I/O (reading a large file) and CPU (parsing and calculating 1B rows) intensive. So which approach is better?
Answer: While Bun is very good at I/O, it’s single threaded, meaning it only uses one CPU core.
If we want to run a bunch of CPU intensive tasks very fast, we need as much CPU cores that we can get our hands on. Also, the worker approach scales a lot easier in a deployed environment. So let’s go with that.
💡 What about node:cluster?
I also looked into Bun’s node:cluster but that seemed more optimized for HTTP requests rather than CPU tasks.
Let’s get into it.
const CPU_COUNT = os.cpus().length;
// os.availableParallelism(); if you're running on Docker
const fileChunks = createChunks(filePath, CPU_COUNT);
// Create a worker for each file chunk
const workers: Promise<WorkerResult>[] = fileChunks.map((fileChunk, index) => {
const worker = new Worker("./worker.ts", {
startByte: fileChunk.start,
endByte: fileChunk.end,
});
worker.on("message", () => {
// use a hash table to aggregate min/max/avg per station
});
};
const results = await Promise.all(workers);
I’m partitioning the file into chunks of size X (based on how many CPU cores we have - in my case, 14 cores) and telling each worker to process its assigned chunk.
Leave No Line Behind
To create the chunks, you have to split them evenly by Bytes. For simplicity, let’s assume it’s 1 GB per chunk. Chunk 1 gets Bytes at position 0 to 999, chunk 2 gets positions 1000 to 1999, and so on.
In theory, this makes sense. But I ran into an issue. I was losing some rows while creating these chunks (ex. ending up with less than 1B rows). Can you guess what could be wrong with this logic?
Turns out that you can’t just split chunks by Bytes blindly, because it doesn’t guarantee that you’ll end each chunk in a clean newline, resulting in lost data. In its current form, you can have a chunk with a row that’s cut in the middle instead of a newline \n character.
You can accidentally end up with a file chunk that ends like this, since we're indexing by Bytes:
Chunk1
...Baghdad;29.3\nNdola;37.2\nLos Angel
^^^^^
"Los Angeles" row sits between
Chunk1 and Chunk2.
Chunk2
eles;25.8\nTel Aviv;28.9...
^^^^
To fix this, we have to make sure every chunk ends in a proper newline character. We add a new function, getPreviousNewlinePosition, which starts at the end of a chunk and moves backward to find the first newline character. This position is used as the chunk’s ending byte.
(while creating Chunk1)
--
t=0
Chunk1
...Baghdad;29.3\nNdola;37.2\nLos Angel
^
Chunk1's current end position.
Walk backwards until you find a \n.
--
t=1
...Baghdad;29.3\nNdola;37.2\nLos Angel
^^
Found a new line. Marking this as the
new end position for Chunk1
--
t=2
Chunk2
Los Angeles;25.8\nTel Aviv;28.9...
^^
Now the next chunk starts in "Los Angeles" as expected
Implementation:
function getPreviousNewlinePosition(startingByteOffset: number, fd: number): number {
const CHAR_NEWLINE = '\n'.charCodeAt(0);
const CHUNK_SIZE = 1024 * 1024; // 1MB chunks
const BUFFER = new Uint8Array(CHUNK_SIZE);
let searchEndByte = startingByteOffset;
// Search backward in chunks
while (searchEndByte > 0) {
const searchStartByte = Math.max(0, searchEndByte - CHUNK_SIZE);
const bytesRead = fs.readSync(fd, BUFFER, 0, CHUNK_SIZE, searchStartByte);
if (bytesRead === 0) return -1;
// Scan the current buffer window backwards
// until you find the first '\n' character
for (let i = bytesRead - 1; i >= 0; i--) {
if (BUFFER[i] === CHAR_NEWLINE) {
// Newline found. Return the byte position where we found it
const newlineByteOffset = searchStartByte + i;
return newlineByteOffset;
}
}
searchEndByte = searchStartByte;
}
return -1;
}
Putting it all together:
function createChunks(filePath: string, cpuCount: number): Array<{start: number, end: number}> {
const fileStats = fs.statSync(filePath);
const FILE_SIZE = fileStats.size;
// open the file once and reuse the file descriptor for all readSync() operations
const fd = fs.openSync(filePath, "r");
const approxChunkSize = Math.floor(FILE_SIZE / cpuCount);
const byteChunks: Array<{start: number, end: number}> = [];
let cursor = 0; // Start of next chunk
try {
for (let i = 0; i < cpuCount; i++) {
let currentChunkLastByte: number;
const isLastChunk = i === cpuCount - 1;
if (isLastChunk) {
currentChunkLastByte = FILE_SIZE - 1;
} else {
// Ends at position 'approxChunkSize - 1' since cursor is 0-indexed
const tentativeChunkEndPosition = cursor + approxChunkSize - 1;
// Calculate the actual chunk end position by finding the previous newline before the tentative end.
// This ensures chunks contain complete lines and don't truncate station names.
const chunkEndPos = getPreviousNewlinePosition(tentativeChunkEndPosition, fd);
if (chunkEndPos === -1) {
// No newline found, we're at the end of the file
currentChunkLastByte = FILE_SIZE - 1;
} else {
currentChunkLastByte = chunkEndPos;
}
}
byteChunks.push({
start: cursor,
end: currentChunkLastByte
});
// Next chunk starts after the last byte of the current chunk
// For chunks that end at a newline, we want the next chunk to start at the character after the newline
cursor = currentChunkLastByte + 1;
// If we've reached the end of file, break out of the loop
if (cursor >= FILE_SIZE) break;
}
} finally {
fs.closeSync(fd);
}
return byteChunks;
}
Perfect. Now that we can create clean chunks with no lines cut off, we’re ready to introduce workers. This part is fairly straightforward: create N workers (one for each CPU core). Each worker is responsible for reading its assigned file chunk, parsing the data and aggregating the statistics.
Creating the worker:
const CPU_COUNT = os.cpus().length;
const fileChunks = createChunks(filePath, CPU_COUNT);
// Create a worker for each file chunk
const workers: Promise<WorkerResult>[] = fileChunks.map((fileChunk, index) => {
const worker = new Worker("./worker.ts", {
filePath,
startByte: fileChunk.start,
endByte: fileChunk.end,
});
worker.on("message", () => {
// use a Map to aggregate min/max/avg per station
});
};
const results = await Promise.all(workers);
// Additional math to aggregate across all workers
And then each worker (omitted some code for brevity):
// worker.ts
async function processFileChunk() {
const { filePath, startByte, endByte }: WorkerData = workerData;
const stats: Record<string, StationStats> = {};
try {
// Setup for reading + parsing the file
const stream = createReadStream(filePath, {
start: startByte,
end: endByte,
highWaterMark: 1024 * 1024 * 1, // 1MB buffer (1MB was the sweetspot for me)
});
const rl = createInterface({
input: stream,
crlfDelay: Infinity, // 'Infinity' means it handles both \n and \r\n correctly
});
// Parse each line and aggregate statistics
rl.on("line", (line: string) => {
const parsedLine = parseLine(line);
const { station, temperature } = parsedLine;
// ...aggregate statistics for stations
});
const result: WorkerResult = {
workerId,
rowsProcessed,
processingTime,
stats,
};
// Send result back to main thread
if (parentPort) {
parentPort.postMessage(result);
}
} catch (error) {
// error handling
}
}
Now we have a working script! It currently runs in ~18.65 seconds. I’m sure we could do better, but where? I brainstormed through some ideas and my hunch is that createReadStream is a low hanging fruit - it decodes each line to utf-8, which feels expensive.
Finishing Touches: Decoding Bytes By Hand
In order to avoid parsing every token to string, we have to parse each byte manually by implementing our own parsers using charCodeAt(). This way we save cpu cycles by using raw Buffer operations instead of readline. Luckily, there’s a finite amount of tokens we expect to see:
- newlines
\n - semicolons
; - digits
0-9 - decimals
. - dashes for the negative sign
-
And the algorithm is actually pretty straightforward:
- For a given line, look for the semicolon. Any character before that is the station name, anything after that is the temperature value.
- Check for dashes
-in case the value is negative - Check for digits to evaluate the number
- Check for decimals
- Build the number from digits in two parts - the integer part and decimal part
Here's the algorithm visualized:
t=0
Tel Aviv;33.9
^
Start loop here.
---
t=1
Tel Aviv;33.9
^
OK I'm at semicolon. Now I'm ready to figure out the station name and temperature.
---
t=2
Tel Aviv;33.9
^
Peek at all the chars to the LEFT; that's the station_name.
Peek at all the chars to the RIGHT; that's the temperature float.
Implementation:
const ASCII_0 = '0'.charCodeAt(0);
const ASCII_9 = '9'.charCodeAt(0);
const ASCII_DECIMAL = '.'.charCodeAt(0);
const ASCII_MINUS = '-'.charCodeAt(0);
const ASCII_SEMICOLON = ';'.charCodeAt(0);
function processLineFromBuffer(
buffer: Buffer,
start: number,
length: number,
stats: Map<string, StationStats>
) {
// Find semicolon position
let semicolonPos = -1;
for (let i = start; i < start + length; i++) {
const isSemicolon = buffer[i] === ASCII_SEMICOLON;
if (isSemicolon) {
semicolonPos = i;
break;
}
}
// Extract station name (trim whitespace)
let stationStart = start;
let stationEnd = semicolonPos;
const station = buffer.toString('utf8', stationStart, stationEnd);
// Extract temperature value cursors (all values after the semicolon)
const tempStart = semicolonPos + 1;
const tempEnd = start + length;
// Skip leading whitespace for temperature
let tempPos = tempStart;
// =========================================================================
// Build the temperature value from the digits, decimal, and negative sign
// =========================================================================
let temperature = 0;
let isNegative = false;
let hasDecimal = false;
let decimalDivisor = 1;
const detectedNegativeSign = buffer[tempPos]! === ASCII_MINUS;
if (detectedNegativeSign) {
isNegative = true;
tempPos++;
}
const isDigit = (char: number) => char! >= ASCII_0 && char! <= ASCII_9;
for (let i = tempPos; i < tempEnd; i++) {
const char = buffer[i];
if (isDigit(char!)) {
// Convert ASCII digit to number
// Ex. ASCII code 55 - ASCII_0 (code 48) = 7
const digit = char! - ASCII_0;
if (hasDecimal) {
// Build the decimal value from the digits
decimalDivisor *= 10;
temperature += digit / decimalDivisor;
} else {
// Build the integer value from the digits
temperature = temperature * 10 + digit;
}
} else if (char! === ASCII_DECIMAL) {
hasDecimal = true;
}
}
if (isNegative) {
temperature = -temperature;
}
// =========================================================================
// Update min/max/sum/cnt stats
// =========================================================================
let stationStats = stats.get(station);
if (!stationStats) {
stationStats = {
sum: temperature,
cnt: 1,
min: temperature,
max: temperature,
};
stats.set(station, stationStats);
} else {
stationStats.sum += temperature;
stationStats.cnt += 1;
// Avoid doing Math.min/max to avoid function call overhead
if (temperature < stationStats.min) {
stationStats.min = temperature;
}
if (temperature > stationStats.max) {
stationStats.max = temperature;
}
}
}

…And that’s it! The program now runs in 9.22 seconds. We just shaved over 9 seconds with this approach!
❯ bun run main.ts measurements.txt
🟢 COMPLETE! 🟢
• Total rows processed: 1,000,000,000
• Total time: 9.22s
• Average throughput: 53,641,608 rows/second
Not bad for Javascript!
Final Tally
️9.22 seconds 🏁
My Takeaways
It was fun to dig into some of Bun and Javascript’s internals to understand its limitations around CPU and memory management. I noticed very quickly that in order to do anything larger than a few gigabytes, you have to start thinking at the lower level - considering Uint8Array’s 4GB limitation, the fact that Bun can only use one CPU core, etc. Not something I do often when I'm writing Typescript 😬.
I also found the worker pattern in JS very clunky - it's slightly annoying to separate files from parent to worker processes as you’re writing code (vs something like golang where goroutines feel natural).
Now I'm curious how the implementation would look in something like Rust or Golang, where lower level primitives are much more efficient!